Efficient distance querying in MySQL
November 8, 2021
In one of my applications at work, we're storing the latitude and longitude of approximately 6 million properties across the state of Texas. Oftentimes our users will need to search for properties that are near each other.
An example of that request would be: "show me other properties that are within 1 mile of this property I'm looking at."
We can take advantage of MySQL's ST_Distance_Sphere function to make this calculation easy, but there are a few extra
things we can do to make this kind of search much, much faster.
Calculating Distance in MySQL
There is an excellent blog post on the
Tighten website that introduces the concept of haversine formulas, and the ST_Distance_Sphere function. It's a great
read if you aren't already familiar with the concept.
The TL;DR of it is this: MySQL 5.7 introduced ST_Distance_Sphere, a native function to calculate the distance between
two points on Earth.
To get the distance between two points, you call the function with the two points as the arguments:
-- Returns distance in meters.select ST_Distance_Sphere( point(-87.6770458, 41.9631174), point(-73.9898293, 40.7628267))This will give you the distance in meters, which you can then convert to miles if needed:
-- Returns distance in miles.select ST_Distance_Sphere( point(-87.6770458, 41.9631174), point(-73.9898293, 40.7628267)) * .000621371192Basic Filtering by Distance
Armed with this function, you can use it to filter out results that are more than e.g. 1 mile from a target point:
select address_idfrom geo_datawhere ( ST_Distance_Sphere( point(longitude, latitude), -- Columns on the geo_data table point(-97.745363, 30.324014) -- Fixed reference point ) *.000621371192 ) <= 1; -- Less than one mile apartBased on our "point of interest" (-97.745363, 30.324014), we can figure out all the other records that lie within a 1-mile radius.
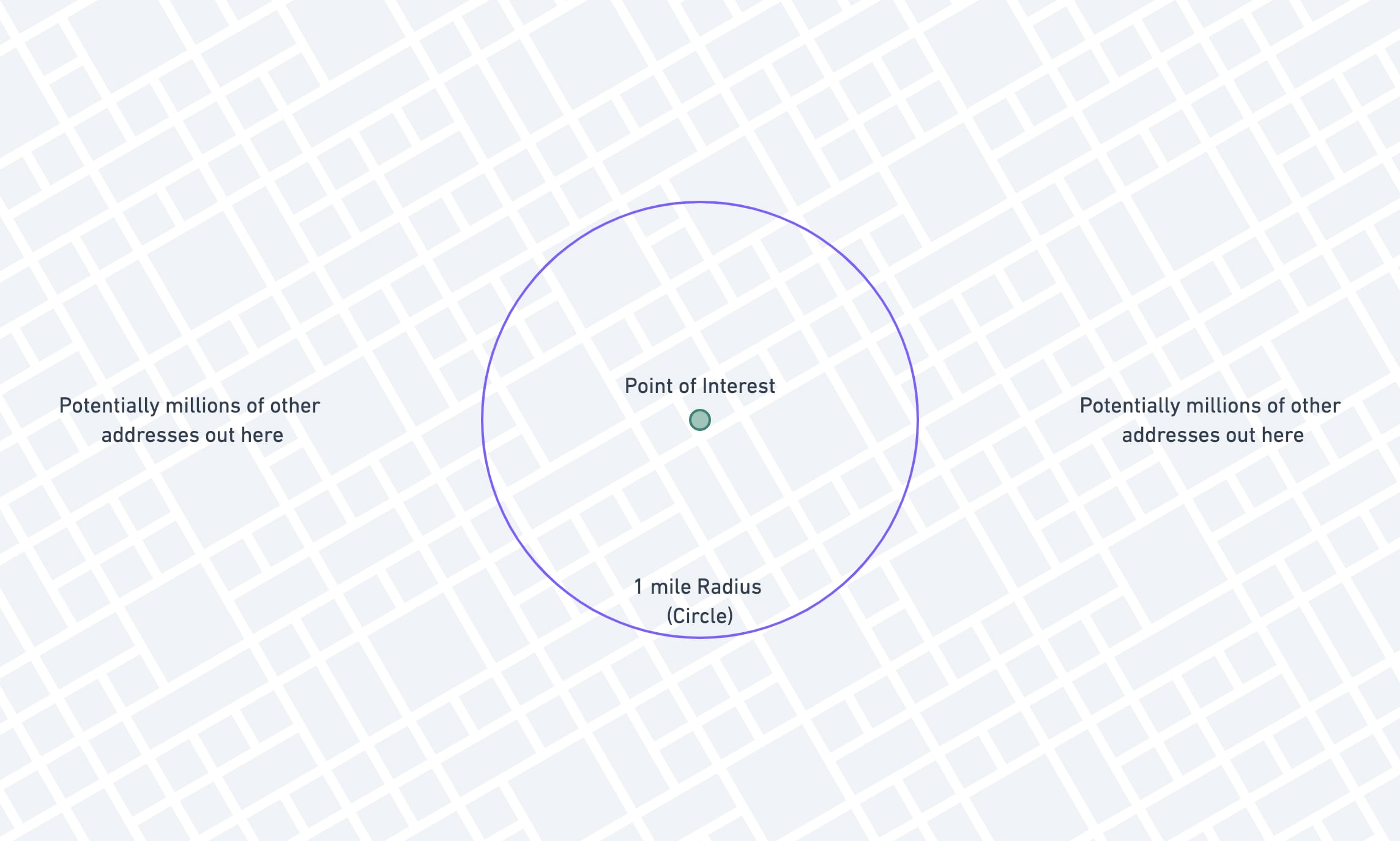
This is a great start, because it gives you results that are 100% correct, which is pretty important! The downside to this method is that it is incredibly slow. MySQL can't use any indexes on this query, because the columns are hidden in a calculation.
Once you get over a relatively small number of records, this solution will no longer be viable. Running this on our ~6 million rows takes more than 10 seconds!
Running Explain on this query shows why:
{ "select_type": "SIMPLE", "table": "geo_data", "type": "ALL", "possible_keys": null, "key": null, "key_len": null, "ref": null, "rows": 4670254, "filtered": 100.00, "Extra": "Using where"}Type = all shows us that it has to scan the entire table, and then use a where to eliminate rows after they have
been retrieved.
Let's see how we can fix this.
Querying Against a Constant
The very first thing we're going to do is extremely minor, but worth doing to illustrate a broader principle. Instead of converting the distance on every row from meters to miles, we're going to convert our search criteria from miles to meters once.
select address_idfrom geo_datawhere ( ST_Distance_Sphere( point(longitude, latitude), -- Columns on the geo_data table point(-97.745363, 30.324014) -- Fixed reference point ) ) <= 1609.34400061; -- Less than one mile apart, in meters The principle here is to minimize calculations that the database has to do, wherever you can. This one won't do much for us though, unfortunately!
Adding a Bounding Box
The first major improvement we can make is to add a "gross bounding box" to our query to lop off huge numbers of rows that don't even get close to meeting our needs. We call it a "gross" bounding box because it isn't very accurate, but we'll solve for that later.
Here's what we're adding:
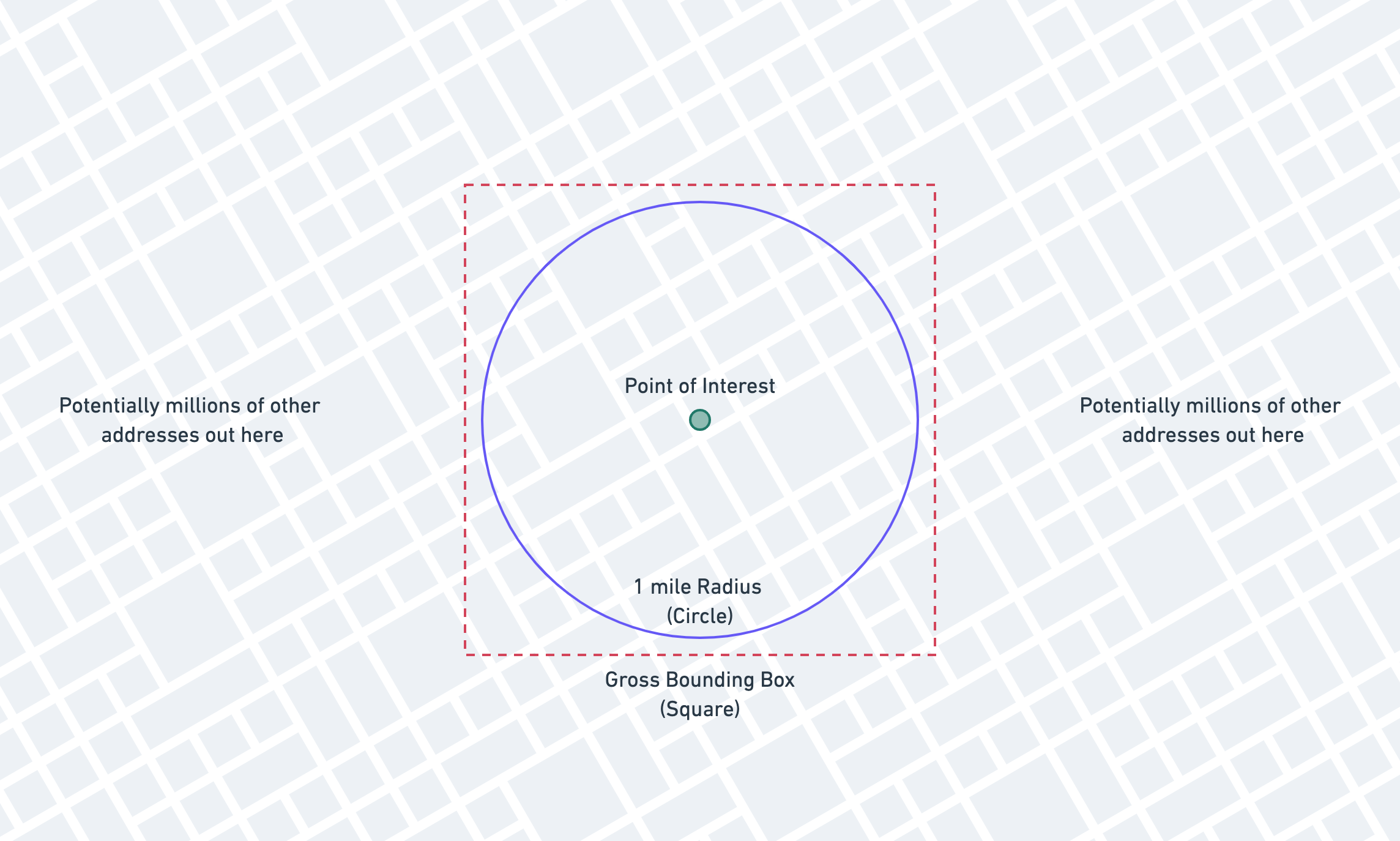
The theory for the bounding box is that we'll be able to take advantage of standard indexes to vastly reduce the number
of records that we need to run the
ST_Distance_Sphere function on.
We need to calculate the red box now, based on the blue circle. We'll do this in a Laravel application, but you can do it in whichever language you use.
Here's the PHP function we'll use to calculate a bounding box, given a latitude, longitude, and distance in miles. (It's an adaptation of a class by Anthony Martin.)
Note that you don't need to understand all the math here (it's a lot!), just that this function produces a bounding box.
public static function boundingBox($latitude, $longitude, $distance){ $latLimits = [deg2rad(-90), deg2rad(90)]; $lonLimits = [deg2rad(-180), deg2rad(180)]; $radLat = deg2rad($latitude); $radLon = deg2rad($longitude); if ($radLat < $latLimits[0] || $radLat > $latLimits[1] || $radLon < $lonLimits[0] || $radLon > $lonLimits[1]) { throw new \Exception("Invalid Argument"); } // Angular distance in radians on a great circle, // using Earth's radius in miles. $angular = $distance / 3958.762079; $minLat = $radLat - $angular; $maxLat = $radLat + $angular; if ($minLat > $latLimits[0] && $maxLat < $latLimits[1]) { $deltaLon = asin(sin($angular) / cos($radLat)); $minLon = $radLon - $deltaLon; if ($minLon < $lonLimits[0]) { $minLon += 2 * pi(); } $maxLon = $radLon + $deltaLon; if ($maxLon > $lonLimits[1]) { $maxLon -= 2 * pi(); } } else { // A pole is contained within the distance. $minLat = max($minLat, $latLimits[0]); $maxLat = min($maxLat, $latLimits[1]); $minLon = $lonLimits[0]; $maxLon = $lonLimits[1]; } return [ 'minLat' => rad2deg($minLat), 'minLon' => rad2deg($minLon), 'maxLat' => rad2deg($maxLat), 'maxLon' => rad2deg($maxLon), ];}With this helper function, we can generate the bounding box picture above and add it to our query using a Laravel query scope:
public function scopeWithinMilesOf($query, $latitude, $longitude, $miles){ $box = static::boundingBox($latitude, $longitude, $miles); $query // Latitude part of the bounding box. ->whereBetween('latitude', [ $box['minLat'], $box['maxLat'] ]) // Longitude part of the bounding box. ->whereBetween('longitude', [ $box['minLon'], $box['maxLon'] ]) // Accurate calculation that eliminates false positives. ->whereRaw('(ST_Distance_Sphere(point(longitude, latitude), point(?,?))) <= ?', [ $longitude, $latitude, $miles / 0.000621371192 ]);}Using this scope will now produce the following SQL:
select address_idfrom geo_datawhere latitude between 30.30954084441 and 30.33848715559 -- Bounding box latitude and longitude between -97.76213017291 and -97.72859582708 -- Bounding box longitude and ( ST_Distance_Sphere( point(longitude, latitude), -- Columns on the geo_data table point(-97.745363, 30.324014) -- Fixed reference point ) ) <= 1609.34400061; -- Less than one mile apartWe're using the gross bounding box to get close and then using the ST_Distance_Sphere to get accurate.
The bounding box will give us some false positives (pictured below), but the expensive ST_Distance_Sphere cleans those up after MySQL has pulled the vastly smaller dataset.
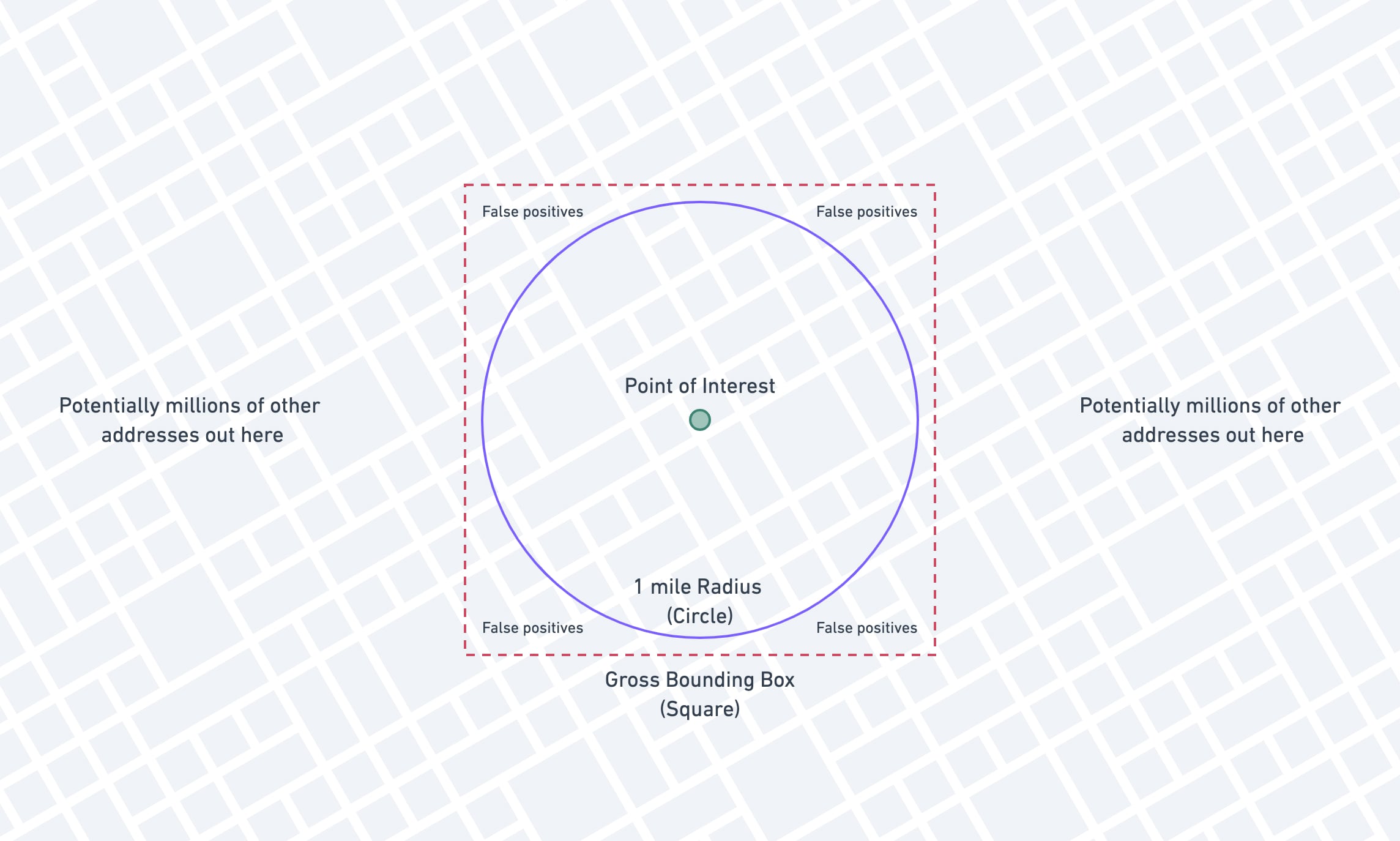
Since we've changed our query up a bit, let's add some indexes onto the latitude and longitude columns and see if this is any better. We're going to add a compound index on both latitude and longitude, but this won't work for reasons I'll explain later.
Schema::table('geo_data', function (Blueprint $table) { // Don't copy-paste this, it won't work like you hope! $table->index(['latitude', 'longitude']);});Let's take a look at the EXPLAIN output after having added that index:
{ "select_type": "SIMPLE", "table": "geo_data", "type": "range", "possible_keys": "geo_data_latitude_longitude_index", "key": "geo_data_latitude_longitude_index", "key_len": "6", "ref": null, "rows": 109062, "filtered": 3.63, "Extra": "Using index condition; Using where"}We're already in a much better state, and could probably stop here and be fine. We see that the access type has
changed from ALL to range, and MySQL is able to use the new geo_data_latitude_index we've added. You'll notice
that the number that MySQL thinks it might have to inspect has dropped from several million to ~110,000.
A win all around!
The only problem with this approach is that MySQL is not able to take full advantage of the compound index because we
are using the between operator. With a compound index, MySQL works from left to right using as many columns as it can,
stopping when it reaches the first range condition. (It can do "loose scans," but they're nowhere near as efficient,
and a topic for another day.)
If this is fast enough for your needs, you can certainly stop here! But if not, there's one more thing we can try.
Generated Columns and Equality Indexes
We're going to try to work our way around the issue of MySQL only being able to effectively use one part of the compound index.
MySQL can use every part of an index provided it's an equality check instead of a range, or provided that the range
is the last column in the index. We're going to take advantage of that by changing our between (range) query to
a where in (multiple equality) query.
The first thing we'll do is add a stored generated column. Stored generated columns are columns that actually exist on
disk and can be indexed, but are kept up to date by MySQL itself. You can think of them as similar to calculated
attributes.
Using Laravel, we're going to add the column:
Schema::table('geo_data', function (Blueprint $table) { // The 1000 factor is dependent on your application! $table->mediumInteger('lat_1000_floor')->storedAs('FLOOR(latitude * 1000)'); // Compound index covering our new column and the old longitude column. $table->index(['lat_1000_floor', 'longitude']);});Again what we're doing here is trying to use indexes to very quickly approximate the truth, and then use the expensive function to calculate the absolute truth.
1000 is a totally arbitrary factor. If your users are searching very wide radii, you'll need to decrease your factor. Our users primarily search for properties within 1 to 3 miles.
This new column takes the latitude, multiplies it by 1000, and floors it. It can be stored as a medium integer.
| id | latitude | lat_1000_floor | longitude ||----|-----------|----------------|------------|| 1 | 30.254520 | 30254 | -97.762064 || 2 | 30.254111 | 30254 | -97.761687 || 3 | 30.253353 | 30253 | -97.762387 || 4 | 30.253652 | 30253 | -97.762061 || 5 | 30.251918 | 30251 | -97.763522 || 6 | 30.252478 | 30252 | -97.762851 || 7 | 30.255021 | 30255 | -97.761766 || 8 | 30.255231 | 30255 | -97.761637 || 9 | 30.255748 | 30255 | -97.761317 || 10 | 30.255317 | 30255 | -97.761082 |Now we're going to do some trickery to make our query use this lat_1000_floor as an equality check, instead of a range
check.
We're going to calculate our bounding box as we did before, but then we'll modify the latitude to conform to the
new lat_1000_floor column.
$box = static::boundingBox($latitude, $longitude, $miles); // Convert the latitudes to tranches $box['minLat'] = (int)floor($box['minLat'] * 1000);$box['maxLat'] = (int)ceil($box['maxLat'] * 1000);Our $box variable now looks something like this:
[ "minLat" => 30309, "maxLat" => 30339, "minLon" => -97.762130172913, "maxLon" => -97.728595827087,]This isn't super helpful, because it seems like we're still going to apply minLat and maxLat using a between
operator. This is where the trickery comes in!
Because this is a bounded, finite, relatively small range, we can manually fill out the range and use an in instead
of between.
MySQL treats
in(1, 2, 3)queries much differently thanbetween 1 and 3. Some databases treatIN()as a shorthand for multipleORstatements, but MySQL sorts the values and is able to use a fast binary search.
With this knowledge, we can fill out the range ourselves:
$box = static::boundingBox($latitude, $longitude, $miles); // Convert the latitudes to tranches$box['minLat'] = (int)floor($box['minLat'] * 1000);$box['maxLat'] = (int)ceil($box['maxLat'] * 1000); // Fill out the range of possibilities. $lats = range($box['minLat'], $box['maxLat']);This fills out the range of possibilities:
[ 30309, 30310, 30311, 30312, 30313, 30314, 30315, 30316, 30317, 30318, 30319, 30320, 30321, 30322, 30323, 30324, 30325, 30326, 30327, 30328, 30329, 30330, 30331, 30332, 30333, 30334, 30335, 30336, 30337, 30338, 30339,]Now all we have left to do is bind it to the query!
public function scopeWithinMilesOf($query, $latitude, $longitude, $miles){ $box = static::boundingBox($latitude, $longitude, $miles); // Convert the latitudes to tranches $box['minLat'] = (int)floor($box['minLat'] * 1000); $box['maxLat'] = (int)ceil($box['maxLat'] * 1000); // Fill out the range of possibilities. $lats = range($box['minLat'], $box['maxLat']); $query // Latitude part of the bounding box using the // generated column and `in` equality check. ->whereIn('lat_1000_floor', $lats) // Longitude part of the bounding box, using the // original column and `range` check. ->whereBetween('longitude', [ $box['minLon'], $box['maxLon'] ]) // Accurate calculation that eliminates false positives. ->whereRaw('(ST_Distance_Sphere(point(longitude, latitude), point(?,?))) <= ?', [ $longitude, $latitude, $miles / 0.000621371192 ]);}The scope now produces the following SQL:
select address_idfrom geo_datawhere lat_1000_floor in ( 30309, 30310, 30311, 30312, 30313, 30314, 30315, 30316, 30317, 30318, 30319, 30320, 30321, 30322, 30323, 30324, 30325, 30326, 30327, 30328, 30329, 30330, 30331, 30332, 30333, 30334, 30335, 30336, 30337, 30338, 30339, ) and longitude between -97.762130172913 and -97.728595827087 and ( ST_Distance_Sphere( point(longitude, latitude), point(-97.745363, 30.324014) ) ) <= 1609.34400061Let's take a look at the EXPLAIN and see if we're getting what we're hoping for:
{ "select_type": "SIMPLE", "table": "geo_data", "type": "range", "possible_keys": "geo_data_longitude_index,geo_data_lat_1000_floor_longitude_index", "key": "geo_data_lat_1000_floor_longitude_index", "key_len": "11", "ref": null, "rows": 6571, "filtered": 100.00, "Extra": "Using index condition; Using where"}You can see that this is even better than our previous result! Previously MySQL thought it was going to have to examine ~110,000 rows to get the result, now it thinks it will only have to examine 6,600! Remember originally, without indexes, MySQL was guessing around 5 million, now we're at 6,600 with a single index, a calculated column, and some work on the application side.
But does our in actually make a difference versus a between? Let's run an explain using a between to see:
explain select address_idfrom geo_datawhere lat_1000_floor BETWEEN 30309 and 30339 and longitude between -97.762130172913 and -97.728595827087 and ( ST_Distance_Sphere( point(longitude, latitude), point(-97.745363, 30.324014) ) ) <= 1609.34400061We get the following result:
{ "select_type": "SIMPLE", "table": "geo_data", "type": "range", "possible_keys": "geo_data_longitude_index,geo_data_lat_1000_floor_longitude_index", "key": "geo_data_lat_1000_floor_longitude_index", "key_len": "11", "ref": null, "rows": 99590, "filtered": 11.11, "Extra": "Using index condition; Using where"}You can see that MySQL is not able to take full advantage of the index, and the number of estimated rows to be inspected jumps back up to ~100,000.
You'll need to assess for your application whether or not 1000 is the right factor when building out your tranches. For our application, most people are usually searching within a 1 to 3-mile radius, so the narrow tranches serve our purposes well. If your users are searching over e.g. 20 mile radii, then you may consider much wider tranches, e.g., a factor 250 or even 100.
As with all things database you'll need to tune these methods with your data and configuration, but something very important to keep in mind is that you can use indexes to quickly approximate the truth.
Knowing a little bit about how your database works can give you a huge leg up when designing more complicated queries!
Addendum: Spatial Indexes
After posting this I received a few very good questions along the lines of "What about spatial indexes?"
I tend to avoid the spatial data columns and methods in MySQL because they're more complicated to work with, have more restrictions, and aren't necessary for my needs. If you need more complex spatial abilities, MySQL has native GEOMETRY,POINT, LINESTRING, and POLYGON types, amongst others.
If you really have a lot of spatial needs, you might even consider Postgres instead of MySQL! I can't speak much to that as I don't use Postgres that often.
I did run a few simple tests to compare the performance of MySQL's spatial indexes versus the methods described here.
The first thing I did was add a POINT column to the table:
// Has to start out nullable, because the table already has rows.Schema::table('geo_data', function (Blueprint $table) { $table->point('location')->nullable();}); // Populate the column. Have to COALESCE because it can't be null!DB::statement( "UPDATE geo_data set location = POINT(coalesce(longitude, 0), coalesce(latitude, 0))");// Change the definition to be not nullable.DB::statement( "ALTER TABLE geo_data CHANGE location location point NOT NULL;"); // Add the spatial index.Schema::table('geo_data', function (Blueprint $table) { $table->spatialIndex('location');});You'll see one of the restrictions of spatial indexes already: they cannot be null. Some of our latitude / longitude columns are in fact null, because we can't find the address. Here we have to coalesce those nulls to 0 so that we can add the spatial index.
Moving onto our query, we'll make use of the boundingBox method again to get our box, and then pass it through to a few special MySQL functions.
public function scopeWithinMilesOfSpatial($query, $miles, GeoData $geoData){ $box = static::boundingBox($geoData->latitude, $geoData->longitude, $miles); $query->whereRaw('ST_CONTAINS(ST_MAKE_ENVELOPE(POINT(?, ?), POINT(?, ?)), location)', [ $box["minLon"], $box["minLat"], $box["maxLon"], $box["maxLat"], ]);}Starting with the inner function, ST_MAKE_ENVELOPE, we make an "envelope" (i.e. box) from our bounding box coordinates. Then we use ST_CONTAINS to see if our location column is within that envelope we just made.
We still need to use the final ST_Distance_Sphere to give us our desired accuracy.
select address_idfrom geo_datawhere st_contains( st_makeEnvelope ( point(-97.762130172913, 30.30954084441), point(-97.728595827087, 30.33848715559) ), location ) and ( ST_Distance_Sphere( point(longitude, latitude), point(-97.745363, 30.324014) ) ) <= 1609.3440006147Running this over our 6 million rows we get results in about 50-60ms. Pretty good!
This is about 20-30ms slower than the version above.
Looking at the EXPLAIN we can see that the new index is being used.
{ "select_type": "SIMPLE", "table": "geo_data", "type": "range", "possible_keys": "geo_data_location_spatialindex", "key": "geo_data_location_spatialindex", "key_len": "34", "ref": null, "rows": 35768, "filtered": 100.00, "Extra": "Using where"}You can see that MySQL is guessing that it will have to inspect ~36,000 rows, which is pretty good, but not quite as good as the tranches + range version from earlier. For reference, here is the EXPLAIN from the tranches version:
{ "select_type": "SIMPLE", "table": "geo_data", "type": "range", "possible_keys": "geo_data_lat_500_floor_longitude_index", "key": "geo_data_lat_500_floor_longitude_index", "key_len": "10", "ref": null, "rows": 7243, "filtered": 100.00, "Extra": "Using index condition; Using where"}Our tranches + range index is able to limit the rows to ~7,000 instead of ~36,000. Also notice that our compound index has a key_len of 10, versus the spatial index key_len of 34, meaning our compound index is much more compact.
Hopefully this helps answer some of the valid questions about spatial indexes. I'm not an expert in spatial indexes, so please make sure that the method you choose suits the needs of your application, and your data!
